In the previous installment of this tutorial we went over how to annotate JPA entities to support database relationships. In this installment, we are going to explain how to save data to your database.
However, if you want to avoid surprises while developing with JPA, you will need a little knowledge about how JPA works under the hood before you start coding.
Persistence Unit
A persistence unit is the association of a set of entity classes with a datasource. It does not associate a set of entity object instances with a datasource. Below is an excerpt of the persistence.xml file we used to configure our persistence unit :
<persistence-unit name="chatserver_jpa_tx" transaction-type="JTA"> <provider>org.apache.openjpa.persistence.PersistenceProviderImpl</provider> <jta-data-source>datasource_chatserver_jpa_tx</jta-data-source> <!-- Entities --> <class>chatserver.model.User</class> <class>chatserver.model.Channel</class> <class>chatserver.model.Attachment</class> <class>chatserver.model.Comment</class> </persistence-unit> Listing 1
In the excerpt above, you can see that we have named our persistence unit chatserver_jpa_tx, and that it is associated with the datasource we’ve named datasource_chatserver_jpa_tx (a MySQL database). You can also see that our persistence unit consists of four entity classes : User, Channel, Attachment, and Comment.
Persistence Context
Once we have defined a persistence unit, the management (e.g.: saving, deleting, updating, etc…) of instances of the classes from our persistence unit is accomplished through the (appropriately named) EntityManager class. In other words, an EntityManager manages instances of entity classes of a persistence unit. In our case, the EntityManager manages instances of the User, Channel, Attachment, and Comment entity classes.
A collection of entity instances that are managed by an EntityManager is called a persistence context. Entities that are manged by a persistence context are referred to as (wait for it…) managed entities. For whatever reason, the distinction between persistence units and persistence contexts seems to be one part of the architecture that causes a lot of confusion. A persistence context is a pool of entity objects that exists at runtime. A persistence unit is a static definition that tells JPA what classes can be instantiated and added to a persistence context at runtime along with what datasource should be used to populate these instances. The TomEE docs describe a persistence context as a cache of entity instances–this is a very good way to think about (a link to this can be found here : TomEE docs – JPA Concepts).
To access an EntityManager for our particular persistence unit, we can ‘inject’ one into an EJB using the @PersistenceContext annotation :
package chatserver.controllers; import javax.ejb.Stateless; import javax.persistence.EntityManager; import javax.persistence.PersistenceContext; import chatserver.model.User; @Stateless public class UserEJB { @PersistenceContext(unitName="chatserver_jpa_tx") private EntityManager em; } Listing 2
Transactions and EJBs
There are many types of EJBs, but we have elected to use Stateless Session Beans–a very memory efficient type of EJB. One of the main reasons we decided to use EJBs at all was because of (a) how lightweight they have become (in JEE 6) both in terms of resource-usage and API, as well as (b) how much they simplify database transactions.
As you can see in the code above (Listing 2), to create a Stateless Session Bean, you merely have to annotate a class with the @Stateless annotation. No additional interfaces or XML configuration are required!
With regard to transactions, you will notice that in Listing 2 we used @PersistenceContext annotation to inject a reference to an EntityManager into our EJB. By obtaining our EntityManager in this way, we are telling JPA that we want to use a container-managed and transaction-scoped EntityManager.
Container-managed means that the JEE server manages the creation, commiting, and rollback of transactions automatically. Transaction-scoped means that a persistence context is created when a transaction first starts, and is destroyed when that transaction ends.
Stateless Session Bean methods interact with transactions in a very appealing way :
- If no transaction is in progress, a new transaction is automatically started at the beginning of the method,
- if a transaction is already in progress when the method is called, then the method will execute within the already-started transaction.
- At the end of the method, the current transaction is committed; unless the transaction was created by the caller (or a method further up the call stack), in which case it is left up to the method that initially created the transaction to commit it.
This behaviour is illustrated in the following diagram :
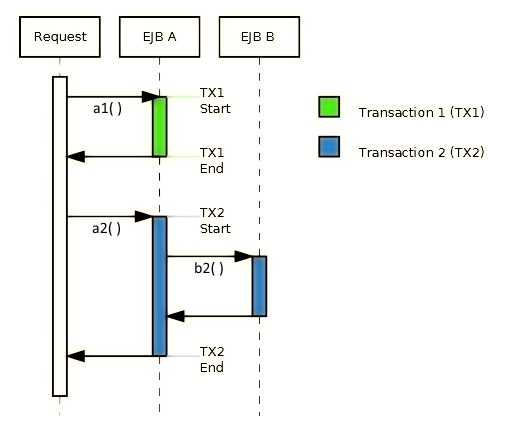
The diagram above illustrates two example transactions : TX1 and TX2. TX1 is started by EJB A in method a1(), and therefore it is EJB A that commits the transaction when method a1() completes (this is done automatically just before a1() returns). TX2 is also started by EJB A, but in this case, EJB A calls method b2() in EJB B before it completes. Both a2() and b2() execute within TX2, however EJB B does not commit TX2 when b2() completes since TX2 was not created in b2(). The transaction only commits when EJB A’s method a2() completes.
Note 1 : The behaviour I’ve described is the default transactional behaviour of Stateless Session Beans. To explore other options, check out the following doc : Container-Managed Transactions – The Java EE 6 Tutorial.
Persistence Context Lifetime and Entity Reference Uniqueness
Persistence Context Lifetime
Recall that the pool (or cache) of entity objects managed by an EntityManager is called its persistence context, and that entities in this pool are referred to as managed entities. When using a container-managed transaction-scoped EntityManager (like we are), the lifetime of its persistence context is tied to the lifetime of a transaction : When a transaction is committed or rolled back, the EntityManager’s persistence context is destroyed. Conversely, a transaction can only be associated with a single persistence context.
Entity Reference Uniqueness
Since a transaction can only be associated with a single persistence context, it means that all EJB methods in the scope of the same transaction are limited to accessing managed entities from the same pool.
For example, consider transaction TX2 of Figure 1; TX2 is interesting because it spans two methods (a2() and b2()). At the beginning of a2(), a persistence context is created and associated with TX2. This persistence context is then destroyed when a2() exits. This means that both methods a2() and b2() interact with the same persistence context (same pool of entity objects)! Because the same entity objects are used by a2() and b2(), JPA is able to provide us with the following gaurantee :
Within the scope of a single transaction, if entities e1 and e2 refer to the same persistent record, then e1 and e2 are the same object.
This means that–within a single transaction–we can use the equality operator to determine if two entities represent the same data. This guarantee is only possible since the system ensures that the same persistence context is used for the entire course of a single transaction. This allows us to use code like the following :
(in an EJB) // determine if a user is a member of a channel boolean isMember(Long userId, Long channelId) { User user = em.find(User.class, userId); Channel channel = em.find(Channel.class, channelId); List<Channel> userChannels = user.getChannelMemberships(); return userChannels.contains(channel); } Listing 3
The caveat is that this only works within a single transaction. Recall diagram 1 above and assume that we call the following code in methods a1(), a2(), and b2().
In a1() :
User userA1 = em.find(User.class, 1);
In a2() :
User userA2 = em.find(User.class, 1);
In b2() :
User userB2 = em.find(User.class, 1);
Then userA2 == userB2 would evaluate to true, since userA2 and userB2 refer to the same record and were retrieved in the same transaction (TX2). However, despite the fact that userA1, userA2, and userB2 all refer to the same record, expressions userA1 == userA2 and userA1 == userB2 both evaluate to false, since userA1 was retrieved in transaction TX1 and userA2, userB2 were retrieved in transaction TX2.
Persisting Entities
Below is an example of how we could persist a User entity.
@Stateless public class UserEJB { @PersistenceContext(unitName="chatserver_jpa_tx") private EntityManager em; public User createUser(String username, String password) { User u = new User(); em.persist(u); user.setPassword(username); user.setUsername(password); return user; } } Listing 4
The first thing we did here was instantiate a new User entity. We then called em.persist(user). Lastly, we set the values for this new entity. This may seem strange to you! Why did we save this User to the database before we set all its values?
The answer is that the ‘persist’ method… is a bit of a misnomer. The persist method does NOT immediately persist an entity to the database. What it does is make our User entity a managed entity.
ALL managed entities are saved to the database when a transaction commits, so unless the current transaction is rolled back, then we are guaranteed that our changes will be saved when it commits.
To summarize, even though we called persist before we set the user’s username and password, this data will still be added to the database, since (a) the user object contained the username and password before the transaction committed, and (b) the user object was managed before the transaction committed.
So if you see a web tutorial on JPA in which the same entity is persisted multiple times in the same method, you may want to re-evaluate how well the author understands JPA…
Retrieving / Modifying Entities
In JPA, there are a huge number of ways to retrieve an entity, or retrieve sets of entities, or retrieve parts of entities etc… However, we are not even going to try and cover all of them. In fact, we will only cover a few of the simplest methods with the hope that this tutorial has given you enough background to start filling in some of the blanks on your own.
The simplest way to retrieve an entity is by using the find() method. To illustrate this, consider the task of updating a user’s password :
@Stateless public class UserEJB { @PersistenceContext(unitName="chatserver_jpa_tx") private EntityManager em; public void updatePassword(Long userId, String password) { User user = em.find(User.class, userId); user.setPassword(password); } } Listing 5
In the first line of the updatePassword() method, we retrieve a User entity from the database using its primary key. By providing the class of the entity we’re searching for, we can get a typed result (e.g.: we don’t have to cast the returned entity from Object to User, for example).
There is another reason I used this example, however. You’ll note we don’t “save” the changes we’ve made in any explicit way. Nonetheless, this change will be saved to the database. The reason is one that we’ve already touched on–the issue of managed entities and EJB transactions.
All entities returned from an EntityManager are managed, and therefore the User entity retrieved in Listing 5 managed and will automatically be saved to the database when the transaction commits. Therefore, the change we made to the user object is automatically persisted to the database.
The Object Graph
One of the most surprising things people discover about JPA, is that JPA does not keep your graph of objects consistent within a persistence context. But what do we mean by ‘your graph of objects’? As with most things–this is best explained with an example.
Consider any bidirectional relationship between entities, such as the One-to-Many / Many-to-One relationship between the Comment and Attachment entities. In this case we have methods Comment.getAttachments() that returns a List of Attachment entities that are contained in a Comment instance. We also have the Attachment.getContainerComment() method that returns the Comment entity that its contained in.
Now suppose we want to add an Attachment to a Comment entity, then we may do something like what we have below :
(in an EJB) Comment comment = new Comment(); em.persist(comment); comment.setAuthor(author); comment.setText("Hi"); comment.setChannel(channel); Attachment attachment = new Attachment(); em.persist(attachment); attachment.setName("icon.png"); attachment.setPreviewLink("http://cloud.com/icon.jpg"); attachment.setSize("1024"); Listing 6.1
According to the JPA spec, we as programmers are responsible for ensuring that both sides of this relationship are consistent. This means that, since this is a bidirectional relationship, it is us that needs to ensure both ends of the relationship refer to each other. In this case, we ‘connect’ both directions of this two-way relationship as follows :
(in an EJB) comment.getAttachments().add(attachment); attachment.setComment(comment); Listing 6.2
JPA GOTCHA : As discussed in the previous lesson, for a @OneToMany or @ManyToOne relationship, we need to create a Collection variable to hold any entities on the Many side of the relationship. For example, in the Comment entity we have a One-to-Many relationship from Comment → Attachment. To hold the Comment’s attachments we added a List<Attachment> reference variable called attachment, however we never assigned this reference an object (e.g.: at no point did we write List<Attachment> attachment = new ArrayList<Attachment>()).
This is fine if we retrieve an Comment entity from an EntityManager since the EntityManager will automatically instantiate an appropriate implmentation of the List<Attachment> interface and assign it to attachment. However, this is not the case with a newly created entity. For this reason, the line
comment.getAttachments().add(attachment)
from Listing 6.2 will throw a NullPointerException since comment.getAttachment() will return null. So the lesson is here is to make sure you assign objects to your Collection variables before using them on newly instantiated entity objects, but entities that you get from an EntityManager will have Collection objects already assigned to these references.
Cascade Types
You’ll note that in Listing 6.1 above, we persisted both the Attachment and Comment entity. But what if a user wants to add 10 attachments to a comment… does this mean we need to loop through all the Attachment entities we received and individually persist each one of them? Luckily, the answer is no.
(in Comment entity) @OneToMany(cascade = CascadeType.PERSIST) @JoinColumn(name = "commentId") public List<Attachment> getAttachments() { return attachments; } Listing 7
All we have to do is tell JPA to automatically persist any Attachment entities added to a Comment’s list of Attachments, and we do that by simply adding a cascade element with a value of CascadeType.PERSIST to the relationship annotation (a @OneToMany annotation in this case). All relationship annotations support the cascade element (e.g.: @OneToMany, @ManyToOne, and @ManyToMany). I recommend adding the cascade = CascadeType.PERSIST element to all of your relationships.
After adding the cascade = CascadeType.PERSIST element to the @OneToMany annotation in listing 7, we can go ahead and safely remove the em.persist(attachment) line in Listing 6.1.
Persistence Context : Flushing and Refreshing
To simplify our ChatServer application, we have been using auto-incremented primary keys for all of our tables, but this can sometimes pose a problem. What if you persist a new entity and need its primary key before the current transaction commits? JPA will not actually save any data to the database before the transaction commits, and therefore it has no way of knowing what primary key the database will generate for the primary key before the transaction commits.
The solution to this is found in the refresh() and flush() methods of the EntityManager. refresh(entity) will immediately save a single entity to the database and then populate it with data from the database (including its primary key).
(in an EJB) User user = new User(); em.persist(user); System.out.println(user.getUserId()); // will print null em.refresh(user); System.out.println(user.getUserId()); // will print the User entity's primary key Listing 8
The flush() method of the EntityManager will save the entire persistence context to the database and populate all the unsaved entities.
Summary
We took a relatively indepth at look at EntityManagers, transactions, persistence contexts, and persistence units. Although it may be a lot of information, the architecture of JPA is quite logical. Hopefully this will prevent you from having to go through the frustration of seemingly inexplicable errors that were due only because of a lack of understanding of how JPA really works.
In the final installment of this series, we will make our ChatServer accessible over the internet via a REST API. To do this we’ll neatly integrate JAX-RS (Java API for Restful Web Services) with our JPA entities.
Until next time!